The duplicate files page in Filerev will show files grouped together where the content is 100% identical. Filerev accomplishes this by generating a unique fingerprint for each file in your Google Drive account. The Filerev software can do this without downloading all of your files from Google Drive, and it is what makes Filerev so fast at finding your duplicates.
Since Filerev determines if a file is a duplicate based on its content, the following file metadata can be different, and Filerev will still categorize the file as a duplicate:
- File Name
- Creation & Modification Date
- Storage Used
- Thumbnail
- File Owner
![]() Note: Filerev is working on adding the feature to view duplicate proprietary Google files such as Google Docs and Google Sheets. If you would like to be notified when this feature is available, please submit your email here.
Note: Filerev is working on adding the feature to view duplicate proprietary Google files such as Google Docs and Google Sheets. If you would like to be notified when this feature is available, please submit your email here.
Why can the storage usage be different for a duplicate file?
Google used to provide free storage space for photos (that were synced from Google Photos) and Google's proprietary documents (sheets, docs, slides, etc). These files that were uploaded when Google storage was free may still be in your account, and they will show storage usage of 0 bytes even though the actual file is larger.
Below is an example of how Filerev will show two files that are identical but are using a different amount of storage in Google Drive.
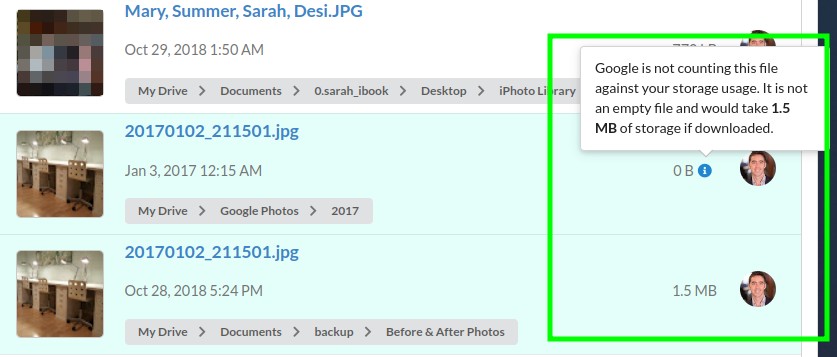
Why are the thumbnails different for my duplicate files?
Most of the time, your duplicate files will have identical thumbnails. However, Filerev gets your thumbnail images from Google Drive, and Google does not always generate an identical thumbnail for identical files. Occasionally, Google will decide not to generate a thumbnail at all for a file. Other times, for file types like videos, it will grab a different frame in the video and generate a different thumbnail. Even though the thumbnails may differ for duplicate files, you can trust that the duplicate files have identical content.
Why are my duplicate PDFs not showing as duplicates?
Filerev determines whether PDFs are duplicates based strictly on their content. However, PDFs often contain hidden internal metadata such as the document's author, unique document identifiers, embedded digital signatures, and software used to create the PDF. If any of this internal metadata differs—even if the visible content looks identical—Filerev considers these files different.
This approach ensures important distinctions, like digital signatures or different document versions, are not mistakenly grouped together. To view the internal metadata of your PDFs, you can open the file in Adobe Acrobat Reader, go to File → Document Properties, and check the details under the Description tab. If your PDFs appear identical but aren't marked as duplicates, differences in these internal metadata fields are likely the reason.
Why are my duplicate images not showing as duplicates?
Filerev identifies duplicate images by comparing the exact file data. This means even small, invisible differences—such as metadata embedded within the image file (e.g., camera details, location data, or software used for editing)—can cause images to have different fingerprints and thus not appear as duplicates. Visually identical images that have been cropped, resized, or slightly modified also produce different file data, preventing Filerev from marking them as duplicates. To verify if your images are truly identical, ensure they haven't been modified in any way, including edits or metadata alterations.